
Rakuten AI 3.0:企業導入でコスト激減?Apache 2.0公開がDX戦略にもたらす衝撃と活用法
2026年3月17日、日本のAI業界に大きな転換点が訪れましたね。楽天グループが、国内最大規模となる約7,000億パラメータの高性能大規模言語モデル「Rakuten AI 3.0」を公開したんです。
これまで「AIは海外製を使うしかない」「コストとセキュリティの板挟みで身動きが取れない」と悩んでいた多くの日本企業にとって、このモデルはまさにゲームチェンジャーになる可能性を秘めています。
本記事では、この「Rakuten AI 3.0」の全貌を速報としてお届けし、なぜ今、企業がこのモデルに注目すべきなのかを徹底解説していきます。従来のモデルとの比較や、ビジネス導入におけるメリットまで、DX担当者や経営層が知っておくべき情報を網羅しましたよ。
Rakuten AI 3.0とは?なぜ「国産最強」と言われるのか
今回発表された「Rakuten AI 3.0」は、単なる「大きなAI」ではありません。経済産業省やNEDOが主導する「GENIACプロジェクト」の一環として開発された、日本企業のビジネス利用に最適化されたフラッグシップモデルなんです。
GPT-4o超えを支える「MoEアーキテクチャ」の凄み
Rakuten AI 3.0の最大の特徴は、「MoE(Mixture of Experts)」というアーキテクチャを採用している点です。
専門用語で難しく聞こえるかもしれませんが、簡単に言うと「巨大な総合病院」のような仕組みです。一つの巨大な脳ですべてを処理するのではなく、「法務が得意な専門家」「プログラミングが得意な専門家」といった複数の専門家ユニット(エキスパート)を配置し、質問に応じて最適な専門家が回答を生成するんです。
これにより、約7,000億という膨大なパラメータを持ちながらも、効率的かつ高速な推論が可能となりました。この効率性が、圧倒的な性能とコストパフォーマンスを両立させている理由ですね。
日本語特化モデルがもたらすビジネス現場での「精度の壁」突破
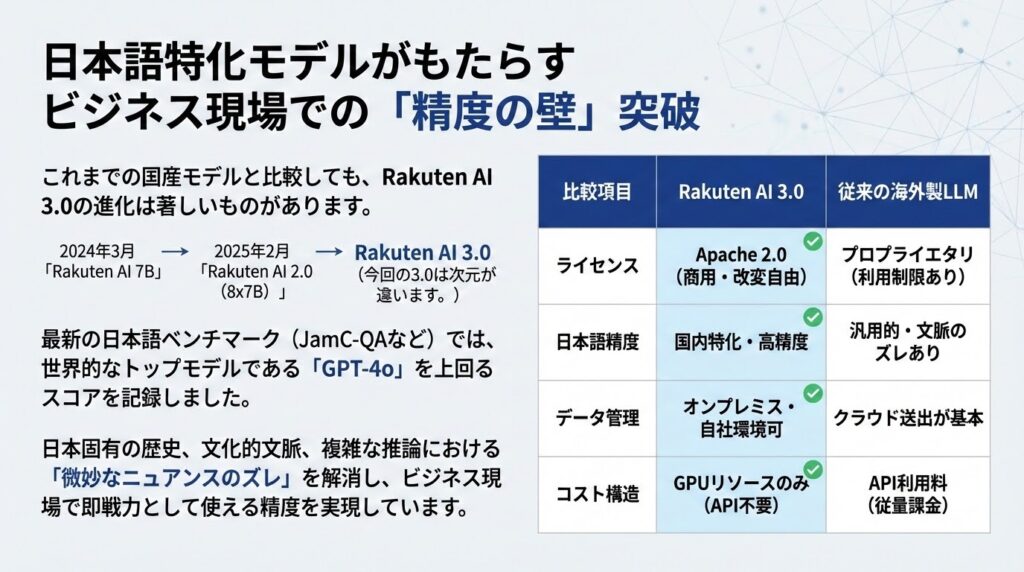
これまでの国産モデルと比較しても、Rakuten AI 3.0の進化は著しいものがあります。
2024年3月に公開された「Rakuten AI 7B」、2025年2月に登場した「Rakuten AI 2.0(8x7B)」と歩みを重ねてきましたが、今回の3.0は次元が違います。最新の日本語ベンチマーク(JamC-QAなど)では、世界的なトップモデルである「GPT-4o」を上回るスコアを記録しました。
日本固有の歴史、文化的文脈、複雑な推論において、海外製LLMではどうしても発生していた「微妙なニュアンスのズレ」を解消し、ビジネス現場で即戦力として使える精度を実現している点は、非常に心強いですよね。


コメント